Trustworthy Generative AI for Sustainable Business Transformation
Approach to Generative AI

The media is abuzz with daily revelations of groundbreaking developments in generative AI, and rightly so. Our research indicates that generative AI has the potential to contribute trillions in value annually. However, it’s essential to heed the lessons learned from past technological revolutions—internet, mobile, social media—where initial excitement and experimentation often gave way to the challenge of extracting significant business value. The current surge in generative AI presents a distinctive chance to apply those lessons, transforming the promise of generative AI into sustainable business value.
When it comes to strategies for developing generative AI capabilities, a variation of the classic “rent, buy, or build” decision emerges. The fundamental principle remains: invest in generative AI capabilities where a company can create a proprietary advantage, and use existing services for those more akin to commodities.
Enterprises can think through the implications of these options as three archetypes:
- Taker – uses publicly available models through a chat interface or an API, with little or no customization. Good examples include off-the-shelf solutions to generate code (such as GitHub Copilot) or to assist designers with image generation and editing (such as Adobe Firefly). This is the simplest archetype in terms of both engineering and infrastructure needs and is generally the fastest to get up and running. These models are essentially commodities that rely on feeding data in the form of prompts to the public model.
- Shaper – integrates models with internal data and systems to generate more customized results. One example is a model that supports sales deals by connecting generative AI tools to customer relationship management (CRM) and financial systems to incorporate customers’ prior sales and engagement history. Another is fine-tuning the model with internal company documents and chat history to act as an assistant to a customer support agent. For companies that are looking to scale generative AI capabilities, develop more proprietary capabilities, or meet higher security or compliance needs, the Shaper archetype is appropriate.
There are two common approaches for integrating data with generative AI models in this archetype. One is to “bring the model to the data,” where the model is hosted on the organization’s infrastructure, either on-premises or in the cloud environment. Cohere, for example, deploys foundation models on clients’ cloud infrastructure, reducing the need for data transfers. The other approach is to “bring data to the model,” where an organization can aggregate its data and deploy a copy of the large model on cloud infrastructure. Both approaches achieve the goal of providing access to the foundation models, and choosing between them will come down to the organization’s workload footprint.
- Maker – builds a foundation model to address a discrete business case. Building a foundation model is expensive and complex, requiring huge volumes of data, deep expertise, and massive computing power. This option requires a substantial one-off investment—tens or even hundreds of millions of dollars—to build the model and train it. The cost depends on various factors, such as training infrastructure, model architecture choice, number of model parameters, data size, and expert resources.
Each archetype has its own costs that tech leaders will need to consider. While ongoing advancements, such as efficient model training approaches and lower graphics processing unit (GPU) compute costs over time, are driving costs down, the complexity of the Maker archetype suggests that most organizations will embrace a mix of Taker and Shaper (to quickly access a commodity service, and to build a proprietary capability on top of foundation models), at least in the near future.
Generative AI at the business touchpoints
As organizations chart their course in the ever-evolving field of generative AI, it’s essential to recognize the diverse range of models at play, varying in size, complexity, and capabilities. Organizations will use many generative AI models of varying size, complexity, and capability. To generate value, these models need to be able to work both together and with the business’s existing systems or applications. For this reason, building a separate tech stack for generative AI creates more complexities than it solves. As an example, we can look at a consumer querying customer service at a travel company to resolve a booking issue. In interacting with the customer, the generative AI model needs to access multiple applications and data sources.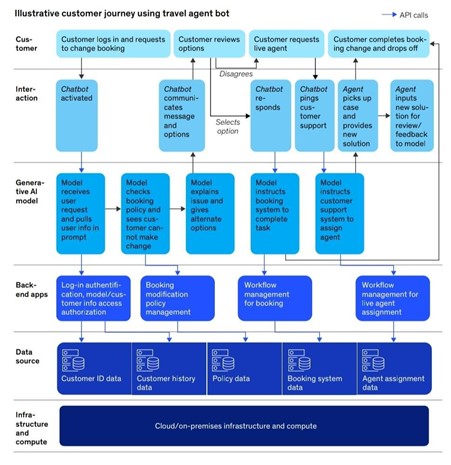 While the Taker archetype operates without the need for extensive coordination, companies aiming to scale generative AI benefits as Shapers or Makers must undergo a technological overhaul guided by CIOs and CTOs. The primary objective is to seamlessly integrate generative AI models into internal systems and enterprise applications, establishing pipelines to diverse data sources. Ultimately, the maturity of a business’s enterprise technology architecture is the key to integrating and scaling its generative AI capabilities.
While the Taker archetype operates without the need for extensive coordination, companies aiming to scale generative AI benefits as Shapers or Makers must undergo a technological overhaul guided by CIOs and CTOs. The primary objective is to seamlessly integrate generative AI models into internal systems and enterprise applications, establishing pipelines to diverse data sources. Ultimately, the maturity of a business’s enterprise technology architecture is the key to integrating and scaling its generative AI capabilities.
Recent strides in integration and orchestration frameworks, exemplified by LangChain and LlamaIndex, have significantly streamlined the process of connecting various generative AI models with other applications and data sources. A range of integration patterns is emerging, including those allowing models to call APIs when responding to user queries—illustrated by GPT-4’s ability to invoke functions. Additionally, there’s a technique known as retrieval augmented generation, where contextual data from an external dataset is provided as part of a user query.
Tech leaders will play a crucial role in defining reference architectures and standard integration patterns for their organizations. This involves establishing standard API formats and parameters that identify the user and the model invoking the API. These efforts are pivotal in ensuring a smooth integration of generative AI capabilities and setting the stage for effective scaling within the business ecosystem.
With this organizational groundwork in place, it becomes increasingly apparent that the capabilities offered by individual Large Language Models (LLMs), may not be exhaustive for the complex challenges posed by real-world scenarios. In the subsequent exploration, we will delve into the limitations of existing LLMs, shedding light on the need for a more encompassing approach to tackle scenarios and define what businesses can take on to utilize the human learnings of this massively-capable technology.
Trustworthy Generative AI
ChatGPT, Gemini, or Any other LLM is not enough.
Despite the success of LLMs in various tasks, they grapple with hallucination issues, particularly in scenarios demanding profound and responsible reasoning. Exemplified by ChatGPT and LLaMA, they have significantly advanced natural language processing, showcasing robust text encoding/decoding capabilities and emergent reasoning abilities. While these models are primarily designed for text processing, real-world scenarios often involve text data intertwined with structured information in graph form (e.g., academic and e-commerce networks). Conversely, there are instances where graph data is enriched with textual details (e.g., molecular descriptions). LLMs also face significant challenges in complex knowledge reasoning tasks. These challenges include inaccuracies in answering questions requiring specialized knowledge, limitations in handling long logic chains and multi-hop reasoning, lack of responsibility, explainability, and transparency, and the expensive and time-consuming nature of their training process. These limitations underscore the need for innovative approaches, such as the integration of external knowledge graphs, to enhance the capabilities of LLMs and address their inherent shortcomings.
Knowledge graphs as an external trustworthy source
To address these challenges, we believe the best approach is to use a combination of LLM-Knowledge Graph (KG), denoted as “LLM-KG.” This paradigm treats the LLM as an agent that interactively explores entities and relations on KGs, leveraging external knowledge for reasoning. The proposed approach, called Think-on-Graph (ToG), implements this paradigm. ToG involves the LLM agent iteratively executing beam search on the KG, uncovering promising reasoning paths, and returning the most likely results. Several well-designed experiments demonstrate the advantages of ToG, including enhanced deep reasoning power compared to traditional LLMs, knowledge traceability, and correctability. ToG also offers a flexible plug-and-play framework for different LLMs, KGs, and prompting strategies without additional training costs. Interestingly, ToG’s performance with smaller LLM models surpasses that of larger models like GPT-4 in certain scenarios, reducing deployment costs.
Recognizing these challenges, a natural and promising solution is to incorporate external knowledge such as knowledge graphs (KGs) to help improve LLM reasoning. KGs offer structured, explicit, and editable representations of knowledge, presenting a complementary strategy to mitigate the limitations of LLMs. Researchers have explored the usage of KGs as external knowledge sources to mitigate hallucination in LLMs. These approaches follow a routine: retrieve information from KGs, augment the prompt accordingly, and feed the increased prompt into LLMs. In this paper, we refer to this paradigm as “LLM ⊕ KG”. Although aiming to integrate the power of LLM and KG, in this paradigm, LLM plays the role of translator which transfers input questions to machine-understandable command for KG searching and reasoning, but it does not participate in the graph reasoning process directly. Unfortunately, the loose-coupling LLM ⊕ KG paradigm has its own limitations, and its success depends heavily on the completeness and high quality of KG.
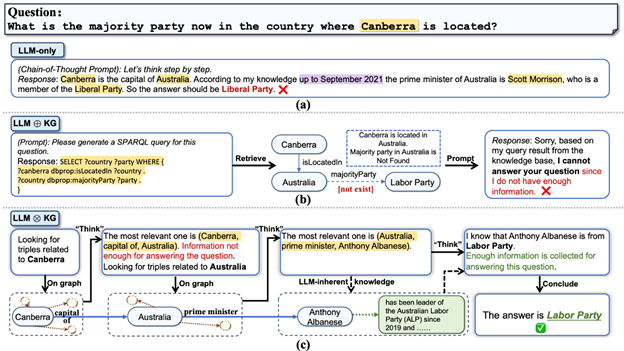
In recent combined research held by IDEA Research, Xiamen University, University of Southern California, Hong Kong University of Science and Technology, and Microsoft Research Asia, authors Jiashuo Sun, Chengjin Xu and colleagues proposed a new tight-coupling “LLM ⊗ KG” paradigm where KGs and LLMs work in tandem, complementing each other’s capabilities in each step of graph reasoning. Figure 1c provides an example illustrating the advantage of LLM ⊗ KG. In this example, the missing relation “majority party” resulting in the failure in Figure 1b can be complemented by a reference triple discovered by the LLM agent with dynamic reasoning ability, as well as the political party membership of Anthony Albanese coming from LLM’s inherent knowledge. In this way, the LLM succeeds in generating the correct answer with reliable knowledge retrieved from KGs. As an implementation of this paradigm, an algorithmic framework is born by the name “Think-on-Graph” (meaning: LLMs “Think” along the reasoning paths “on” knowledge “graph” step-by-step, abbreviated as ToG. ToG allows LLM to dynamically explore a number of reasoning paths in KG and make decisions accordingly. Given an input question, ToG first identifies initial entities and then iteratively calls the LLM to retrieve relevant triples from KGs through exploration (looking for relevant triples in KG via “on graph” step) and reasoning (deciding on the most relevant triples via “think” step) until adequate information through the top-N reasoning paths in beam search is gathered to answer the question (judged by LLMs in “Think” step) or the predefined maximum search depth is reached.
 The advantage of this approach can be abbreviated as:
The advantage of this approach can be abbreviated as:
- Deep Reasoning: Extracts diverse and multi-hop reasoning paths from Knowledge Graphs (KGs), serving as a foundation for Large Language Models (LLMs) to enhance their deep reasoning capabilities. This is particularly beneficial for knowledge-intensive tasks.
- Responsible Reasoning: Explicit and editable reasoning paths provided contribute to the explainability of LLMs’ reasoning processes. This improvement allows for the tracing and correction of the sources of the model’s outputs, ensuring responsible and transparent decision-making.
- Flexibility and Efficiency:
- Operates as a plug-and-play framework, seamlessly adaptable to various LLMs and KGs.
- Within the framework, knowledge updates can be performed frequently through the KG, offering a more efficient alternative to the expensive and slow knowledge updates in LLMs.
- Not only provides a flexible framework but also empowers smaller LLMs (e.g., LLAMA2-70B) to compete effectively with larger counterparts like GPT-4 by enhancing their reasoning abilities through top-N reasoning paths in the beam search algorithm.
Trustworthy Knowledge – The way to success
As we navigate the intricate landscape of innovation and disruption, the role of Think-on-Graph (ToG) in enhancing Large Language Models (LLMs) becomes even more pronounced. The synergy between LLMs and Knowledge Graphs (KGs) not only overcomes the challenges of reasoning limitations but also presents a forward-looking approach to harnessing the power of enterprise knowledge.
Navigating the treacherous waters of innovation and disruption in this digital ocean nowadays, enterprise knowledge is the fuel that propels enterprise growth, the shield that deflects mishaps, and the compass that guides toward success. Why is enterprise knowledge so crucial? It’s simple: Trustworthy knowledge is power. It empowers employees to make informed decisions, solve problems swiftly, and innovate fearlessly. It strengthens the enterprise brand by ensuring consistent quality and customer satisfaction. It even acts as an invisible fortress, safeguarding our intellectual property and competitive edge. Having just knowledge isn’t enough, it’s also about harnessing it, cultivating it, and making it readily accessible to everyone in the organization. That’s where building a Customer Insight comes in.
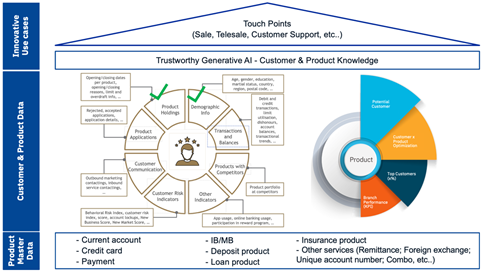
Think of it as a secure, ever-evolving repository of everything valuable that lives within your enterprise:
- Customer 360-degree: Understand your customers’ needs, preferences, and pain points like the back of your hand.
- Best practices: Document and share tried-and-tested workflows, strategies, and operational methods.
- Industry expertise: Stay ahead of the curve by capturing market trends, competitor analysis, and emerging technologies.
- Know-how: Preserve tribal knowledge from seasoned veterans before it walks out the door.
- Sale and Service History: Turn past successes and failures into valuable lessons for future ventures.
However, building such a system requires a shift in mindset. We must move beyond siloed information hoarding and embrace collaborative knowledge sharing. This transformation hinges on three key pillars:
- Building the Ark: The foundation of any robust knowledge system is a comprehensive and easily navigable repository. It must seamlessly integrate diverse forms of information – documents, reports, presentations, and even videos and recordings of expert advice. Intuitive search functionalities and tagging systems are crucial for effortless retrieval.
- Fostering a Culture of Contribution: Encouraging employees to actively contribute their knowledge is paramount. Gamification and reward systems can incentivize participation while knowledge-sharing workshops and mentoring programs can foster a collaborative environment. Remember, knowledge is only truly valuable when it flows freely.
- Continuous Improvement: Just like any living organism, your enterprise knowledge system needs nurturing to thrive. Periodic audits and performance assessments ensure the information remains relevant and accurate. User feedback can guide further iterations and enhancements, keeping the system aligned with evolving needs.
Conclusion
Remember, your Trustworthy Generative AI is a living, breathing entity. Nurture it by constantly adding new knowledge, updating existing information, and keeping it relevant and accessible. Don’t let it become a dusty archive; make it the vibrant heart of your organization, pumping knowledge through its veins and empowering your entire team to reach new heights.
In a world where data is abundant but wisdom is scarce, building your own Enterprise Knowledge Vault is no longer a luxury, it’s a necessity. So, open the doors, unleash the power of knowledge, and watch your company soar.
Author’s note:
In the development of this paper, I have integrated ideas and concepts from various scholarly sources to provide a comprehensive and well-rounded analysis. The following discussion draws upon the works of [Baig, et al] (McKinsey Digital 2023), [Sun, et al] (THINK-ON-GRAPH 2023), and [Luo, et al] (REASONING ON GRAPHS 2023), among others. These sources have significantly contributed to the theoretical framework and understanding presented in this paper.
A quick primer on key terms
Generative AI is a type of AI that can create new content (text, code, images, video) using patterns it has learned by training on extensive (public) data with machine learning (ML) techniques.
Foundation models (FMs) are deep learning models trained on vast quantities of unstructured, unlabeled data that can be used for a wide range of tasks out of the box or adapted to specific tasks through fine-tuning. Examples of these models are GPT-4, PaLM 2, DALL·E 2, and Stable Diffusion.
Large language models (LLMs) make up a class of foundation models that can process massive amounts of unstructured text and learn the relationships between words or portions of words, known as tokens. This enables LLMs to generate natural-language text, performing tasks such as summarization or knowledge extraction. Cohere Command is one type of LLM; LaMDA is the LLM behind Bard.
Fine-tuning is the process of adapting a pretrained foundation model to perform better in a specific task. This entails a relatively short period of training on a labeled data set, which is much smaller than the data set the model was initially trained on. This additional training allows the model to learn and adapt to the nuances, terminology, and specific patterns found in the smaller data set.
Prompt engineering refers to the process of designing, refining, and optimizing input prompts to guide a generative AI model toward producing desired (that is, accurate) outputs.
Exclusive article by FPT IS Technology Expert
Le Viet Thanh
Deputy Director of Data Analysis and Platform Center
FPT Information System Company.










