Basic concepts of Data Store and factors to consider for selecting data stores in applications
In today’s data-driven world, selecting the appropriate data store is crucial for effectively analyzing, managing data, and building applications. With hundreds of data store options available, making the right choice can be challenging. This article aims to provide a comprehensive overview of data stores and offer guidance on selecting the best type for your specific needs.
1. Basic concepts of Data Store
1.1. Data store
A data store is a place to store and manage data. Besides data storage like databases, data stores are also used to store other types of data such as raw files (text, audio, image, video, etc.) and emails. This article will focus on three popular types of data stores: RDBMS, NoSQL database, and Object Store.
1.2. Database
A database is a collection of data managed by a database management system (DBMS). There are two popular types of databases: relational database management systems (RDBMS) and NoSQL databases.
1.3. Distributed database
A distributed database stores data across multiple computers, known as clusters. Each computer in the cluster is called a node.
1.4. RDBMS (Relational Database Management System)
An RDBMS is a database based on relational models, typically containing tables with one-to-one, one-to-many, and many-to-many relationships. It uses Structured Query Language (SQL) to query and update data. While SQL dialects may vary depending on the vendor, they generally comply with the SQL-92 standard.
1.5. NoSQL
The term NoSQL has been a source of confusion since its inception, with some mistakenly believing it to be a replacement for SQL. However, NoSQL actually stands for “Not Only SQL,” referring to a database design that focuses on storage and retrieval rather than tabular design like RDBMS.
1.6. Transaction
A transaction is a collection of operations that accomplish a single purpose, appearing as a single operation to external observers. For example, in an online money transfer transaction, the system must perform a series of actions, such as verifying the sender’s balance, checking the recipient’s account existence, debiting the sender’s account, and crediting the recipient’s account.
1.7. OLTP versus OLAP:
– OLTP (Online Transaction Processing): enables multiple users to perform multiple transactions simultaneously. For example, e-commerce websites that support functions like product viewing and purchasing are OLTP systems.
– OLAP (Online Analytical Processing): enables data analysis, typically using data generated from OLTP systems. For example, in an e-commerce system, calculating sales by month, quarter, or year, and identifying best-selling products are examples of OLAP activities.
1.8. Data Warehouse
A data warehouse is a type of database management system designed to execute queries and analyze historical data. It is often integrated with Business Intelligence (BI) tools to generate reports.
1.9. ACID
ACID stands for Atomicity, Consistency, Isolation and Durability.
– Atomicity: All operations in a transaction must be successful for the transaction to be executed. If any operation fails, the entire transaction is rolled back.
– Consistency: Once a transaction is successfully committed, all future queries to the data affected by the transaction will return consistent results. For example, if a transaction updates the ‘salary’ column in the employee table to 10M, all subsequent queries on that record will consistently return 10M without discrepancies.
– Isolation: Multiple transactions can occur simultaneously without causing data inconsistency in the database.
– Durability: Once a transaction is successful, the changes it made to the data are permanently stored in the database.
1.10. CAP Theorem
The CAP Theorem states that in the presence of a network partition, a distributed database cannot simultaneously guarantee both Consistency and Availability. Only one of these two properties can be chosen.
- Choosing Availability over Consistency:
Suppose there are two services, A and B, with data stored in a key/value store consisting of three nodes. When service A updates the counter value from 6 to 8, the value is stored in the key/value store. However, due to a network partition, only two nodes update the data to 8, while one node still has the value 6. If availability is prioritized over consistency, service B can read the counter value as 6.

- Choosing Consistency over Availability:

Using the same example, if consistency is prioritized over availability, then when service B attempts to read the counter, the system will not respond.
2. Comparison of RDBMS and NoSQL
| NO. | RDBMS | NoSQL |
| 1. | Supports ACID as one of the fundamental properties. | Has very limited support for ACID properties. |
| 2. | Schema: It is necessary to specify the schema during table creation. Every time data is inserted or updated, it must adhere to the data type and table constraints. This process is also called schema-on-write. | No schema needs to be specified beforehand. Data type is considered only when querying data. This process is called schema-on-read. |
| 3. | Can work with structured data effectively. | Can work with structured, semi-structured, and unstructured data. |
| 4. | Typically, OLTP systems are designed to run on a single server. To increase capacity, scaling-up is usually required, which means adding more RAM and CPU to that server. | Scaling out, meaning adding more nodes (servers) to the cluster to increase the capacity. |
| 5. | Data access: Usually done by using SQL, ODBC, or native APIs. | Data access: mostly done by using APIs. However, NoSQL recently has started to support data querying via SQL. |
| 6. | Query pattern: Often executes complex SQL statements, including JOIN multiple tables. | Does not support JOIN operations in most cases. |
| 7. | Performance: Typically improved by partitioning or using index. | Enhances performance through indexing or sharding. |
2.1. Overview of RDBMS
The following table lists today’s most popular types of relational databases.
| NO. | Vendor | Description |
| 1 | Oracle | Oracle leads the market in RDBMS sector. Oracle also owns and provides open source MySQL. Starting from Oracle 12c version, it supports columnar store(*) and JSON data type. |
| 2 | Microsoft | Microsoft SQL Server, alongside Oracle, leads the market. Starting from SQL Server 2016, it also supports columnar store and JSON data type. Microsoft Azure SQL offers cloud-based SQL Server. |
| 3. | Teradata | It focuses on supporting Data warehouse applications. |
| 4. | Amazon | · Amazon Aurora is a MySQL-compatible relational database
· Amazon Relational Database Service (RDS) is a web service that allows users to use leading RDBMS such as: Oracle, Microsoft SQL Server, PostgreSQL, Amazon Aurora, and MariaDB. It provides scaling capabilities and automated management of database systems. · Redshift is used for large-scale data warehousing, handling up to petabytes of data. |
| 5. | IBM | · BM DB2 can run on Windows, Linux, and mainframe platforms.
· DashDB is cloud-based using DB2 core · Netezza Analytics supports data warehousing, and is built on PostgreSQL platform. |
| 6. | Google Cloud SQL provides MySQL, PostgreSQL, and SQL Server databases. | |
| 7. | PostgreSQL | This is the most popular open-source RDBMS, supporting JSON document and key-value data storage. |
| 8. | MemSQL | MemSQL combines storage on both disk and RAM, making it a popular type of In-Memory RDBMS that enables near-real-time data access and processing. |
| 9. | VoltDB | It is a In-Memory RDBMS that allows scaling by cluster. |
2.2. Overview of NoSQL database
NoSQL databases have existed for a long time but gained significant popularity in the 2000s due to the sharp decline in hard drive prices, the exponential increase in data volume, and the necessity to handle not only structured but also semi-structured and unstructured data. There are five main types of NoSQL databases: Key-Value, Document, Columnar, Graph, and Search. We will delve deeper into each type.
2.2.1. Key-Value store
Key-Value stores data in key – value pairs, where the value can encompass various data types such as integers, strings, or arrays.
Common types of Key-Value stores:
| NO. | Vendor/Products | Features |
| 1. | Redis | – Redis is the most widely used key-value database today. It supports both documents and time-series data.
– Redis primarily stores data in memory but also offers disk storage for increasing availability. – Redis is available in both paid and open-source versions. – Redis can be installed on-premise or used via cloud. |
| 2. | Riak | – Riak is a key-value database that offers high availability and robust fault tolerance, making it ideal for applications requiring extremely low downtime. |
| 3. | Memcached | – Memcached, a former leader in the key-value space. However, it is more suited for small applications and static data compared to Redis.
– It uses a multithreaded architecture, unlike Redis, which uses single-threaded approach |
| 4. | Hazelcast | – Hazelcast is designed for importing large volumes of data.
– It offers both open-source and commercial versions, available for on-premise and cloud deployments. |
| 5. | Aerospike | Aerospike stores indexes and data in memory or on SSD. |
Applications suitable for Key-Value stores:
- Applications with high-frequency inserts, such as web session logs. User login sessions are stored into application.
- Applications requiring very fast data writes.
- Applications utilizing data caching to enable quick data query.
- Applications unsuitable for Key-Value stores:
- Applications requiring complex queries or SQL-type data retrieval.
2.2.2. Document store
- Each data line (document) in a document store contains sufficient information to define itself without the need for additional metadata. Data formats can include HTML, XML, or JSON.
- Each document has a primary key.
- ACID properties are supported at the document level, not across the entire database.
- Data retrieval is performed through APIs.
- To enhance performance, the document store utilizes data sharding across multiple nodes in a cluster.
- JSON files, being voluminous, are compressed into Binary JSON (BSON) in document stores.
Applications suitable for Document stores:
- Applications requiring a flexible schema (schemaless), such as e-commerce platforms where each product has different attributes (e.g., books vs. electronics).
- Applications requiring quick data retrieval, especially when migrating from legacy applications from RDBMS systems.
Common types of Document Stores
| NO. | Vendor/Products | Features |
| 1. | MongoDB | – The most common NoSQL database.
– Provide strong sharding capabilities. – Easy to use. |
| 2. | Amazon DynamoDB | – One of the most popular types of cloud databases.
– Support Document stores, key-value, and graph databases (with TitanDB plugin). |
| 3. | Apache CouchDB | – An open-source type
– High performance; Many large organizations switch to CouchDB due to its stability and ease of scalability. |
| 4. | Couchbase | – Developed by the same team as Apache CouchDB, and offers both open-source and commercial versions.
– Compatible with memcached for very fast queries using RAM caching and disk storage. – Widely used by large organizations in its commercial version. |
| 5. | IBM Cloudant | – Use the same core as Apache CouchDB.
– Hosted by IBM with an SLA of up to 99.99%. |
| 6. | MarkLogic | – Initially an XML database, now support both document and search stores. |
| 7. | Microsoft Azure DocumentDB | – Compatible with MongoDB, allow users to write applications using MongoDB and then migrate them to the Azure cloud. |
| 8. | Google Cloud Datastore | – Provide automatic sharding and replication services. |
2.2.3. Columnar store
Columnar store, also known as column-oriented database, stores data on disk in a column format instead of the traditional rows. It accelerates data query performance in data analytics.
For example, consider an Employee table with four columns: ID Number, Last Name, First Name, and Bonus (additional amount received). Traditional databases store data in row-oriented manner, meaning data rows are stored vertically. The row with ID = 513001 is placed above 502333, and each row containing data for all four columns. Now, if we want to analyze data, such as calculating the average bonus for employees, the engine must scan all the rows, sum the bonuses, and divide by the number of rows. This query would be very costly, however, with millions of rows. With a columnar store, table’s data is organized by columns, meaning the columns of the Employee table are flattened and stored horizontally in a row. For instance, all IDs are stored in one row, and all bonus values are stored in another row. The number of rows in a column-oriented store equals the number of columns in the table. To calculate the average bonus, the engine only needs to sum the values in the row containing the bonus data.
- Applications suitable for Columnar stores:
- Analytics applications that require filtering and aggregating data by columns, such as log data analysis.
- Applications storing and analyzing time-series data.
- Applications unsuitable for Columnar stores:
- OLTP applications.
- Applications requiring full ACID properties.
- Applications with a small amount of data.
- Common types of Columnar Stores:
| NO. | Vendor/Products | Features |
| 1. | Apache Cassandra | – Available in both open-source and paid versions on DataStax
– Initially developed by Facebook based on Amazon DynamoDB and Google Bigtable – Access data via SQL-like Cassandra Query Language (CQL) – Support both key-value stores and graph stores. |
| 2. | Apache Hbase | – Open-source, based on Google Bigtable
– Interact closely with the Hadoop ecosystem – Retrieve data using Java, Thrift, and RESTful APIs |
| 3. | Apache Accumulo | – Store data on HDFS
– Support fine-grained access |
| 4. | Amazon Redshift | – Store and process large datasets for data analysis purposes |
| 5. | Snowflake | – Cloud-based, used to build data warehouses and data lakes |
| 6. | SAP HANA | – Store data in RAM, suitable for real-time data analysis. |
| 7. | CockroachDB | – Support both row-oriented and column-oriented storage |
| 8. | MariaDB ColumnStore | – MariaDB’s columnar storage engine, designed for big data analysis |
2.2.4. Graph data store
Hierarchical data is quite common in modern applications. For example, in a company’s employee list, some employees are “bosses” of other employees. RDBMS models this type of data using foreign keys. In the example above, the Employee table might have columns like ID (primary key – PK), Name, Date Of Birth, Gender, ManagerID (foreign key – FK to ID). To find a list of employees for a certain manager, you need to join the Employee table with itself. For an extremely large number of records and a deep hierarchy, this join becomes very costly. Graph stores were created to store complex hierarchical data, making querying much more efficient. In a graph store, data is represented as a graph with nodes, and the relationships between these nodes are edges. This structure allows for queries between nodes by traversing the connecting edges.
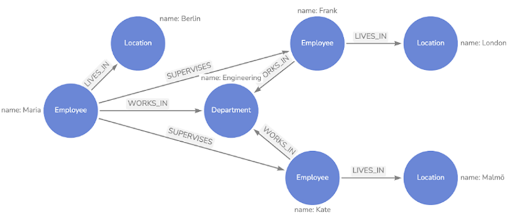
Applications suitable for Graph stores:
– Graph stores are ideal for storing hierarchical data with interconnected relationships, such as social networks.
Applications unsuitable for Graph stores:
– Applications that rely heavily on SQL JOIN operations.
Common types of Graph Stores:
| NO. | Vendor/Products | Features |
| 1. | Neo4j | – The most popular graph store.
– Used to find connections between entities in the “Panama papers” scandal |
| 2. | OrientDB | – Open source
– A hybrid version of document and graph databases |
| 3. | TitanDB | – Initially open source, then acquired by DataStax and integrated into DataStax Enterprise
– A new graph store, JanusGraph, is developed by the team originally behind TitanDB. |
| 4. | JanusGraph | – Developed by the team behind TitanDB
– Open source – Support data retrieval using REST API or High-performance Native API |
2.2.5. Search data store
A search data store enables efficient searching using wildcard, data grouping, and ranking. Two typical algorithms used in search stores are inverted index and TF-IDF. Inverted index will “hash” words in a document into indexes, while TF-IDF will determine the importance of those keywords.
Applications suitable for Search stores:
– Applications requiring effective search capabilities, such as keyword searches in e-commerce platforms or any application needing to search large datasets.
Applications unsuitable for Search stores:
– Applications requiring ACID properties.
Common types of Search stores:
| NO. | Vendor/Products | Features |
| 1. | ElasticSearch | – Open source, based on Apache Lucene Core. Developed by Doug Cutting, the father of Hadoop.
– Currently developed by Elastic company. Commercial version available with advanced features like security, monitoring, visualization, and graph capabilities. – Integrated with the very popular ELK stack, which includes LogStash and Kibana. |
| 2. | Apache Solr | – Open source, based on Apache Lucene Core. Interact closely with the Hadoop ecosystem. |
Some other types of Data Stores
If raw files storage is needed, there are two very popular types of data stores, namely Hadoop Distributed File System (HDFS) and Object Store.
- Object store
Object stores efficiently store raw data, simplifying both storage and retrieval processes.
When to use Object store:
– When requiring storage of raw data at low cost.
– When utilizing big data tools for data retrieval. Most big data SQL-On-Hadoop technologies, such as Apache Drill, Hive, Amazon Athena, Impala, and Presto, support querying data on Object Store.
Common types of Object stores
| NO. | Vendor/Products | Features |
| 1. | Amazon S3 (Simple Storage Service) | – The most popular Object store, one of the most outstanding services of AWS.
– Support durability up to 11 9’s and availability up to 4 9’s. – Offer “cold data” storage through Glacier to secure infrequently accessed data at a very low cost. |
| 2. | Microsoft Azure Blob Storage | – Retrieve data on Azure Storage using REST API, supporting multiple programming languages.
– Data on Azure Storage can be used on applications like Azure Data Lake Store. |
| 3. | Google Cloud Storage | – Retrieve data via RESTful web service. Data will be read-only
– Store data in JSON or CSV format. Support SQL-like querying with results returned in JSON format. |
- HDFS
HDFS is the core of Hadoop big data technology. Data on HDFS is replicated by default into three copies, providing high availability. It can be processed by various analytical tools such as MapReduce, Apache Spark, Apache Hive, Apache Pig, and Apache Impala.
3. Factors to consider for selecting data stores in applications
3.1. Operational workload or analytic workload
Operational workload typically involves OLTP applications that require the database to be optimized for inserts, updates, and transactions with strong ACID properties needed. RDBMS is well-suited for this type.
Analytic workload involves OLAP applications that require the database to be optimized for data reading and performing quantitative operations such as sums, averages, minimums, and maximums. Columnar data stores are ideal for this type of workload.
Additionally, there is a hybrid type called “Hybrid Transactional and Analytical Processing” (HTAP). This is useful for real-time applications like fraud detection. In-memory data stores such as key-value stores are recommended for HTAP scenarios.
3.2. Data storage and query method
Another critical factor influencing the choice of a data store is how data is stored and queried.
Graph stores are suitable for hierarchical data or complex relationships between data points.
Key-Value stores are used when data retrieval is primarily based on keys, regardless of data storage format and data type.
Relational databases (RDBMS) are appropriate for data that is structured and requires quantitative retrieval operations like sum, average, min, and max.
Document stores are optimal when the data has many attributes in the schemas, or contains tags such as JSON or XML.
Object stores are recommended for storing raw files at low cost.
3.3. Costs and experience
Once the type of data store is decided, the choice of a specific database involves considering cost and expertise factors. For instance, opting for an RDBMS like Oracle or Microsoft SQL Server may be feasible with a larger budget, while startups with limited resources might prefer open-source options like PostgreSQL. Additionally, the practical experience of the team also plays a crucial role in the final decision-making process.
In today’s landscape, many applications are deployed using the microservices model, where each service performs distinct functions and utilizes its own data store. This approach often results in applications employing multiple types of data stores simultaneously. Hopefully, this article has provided an overview of various data store types to aid in making informed decisions.
| Exclusive article by FPT IS Business Technology Experts Author Nguyen Viet Cuong – Deputy Director of VioEdu Online Education Center, FPT IS |